Python + Go: Introduction
python go C web theory packages
Table of contents
Python can be slow at the best of times, but sometimes it’s the best option for you, or your team. How can we offset python’s weaknesses with other language’s strengths? Is it worth it to integrate libraries written in other languages for the slow parts of python, and use python for the rest? What are the pros and cons to doing this?
I’ve been experimenting over the last week with this idea, but I’ve had it for a long time. I just didn’t have the right language, or knowledge base to do it well before. Most languages people do this sort of work with are C, C++, Rust or some obscure systems programming language. Go on the other hand is slightly more difficult than python to learn, but not by much. If you’re familiar with static typing, and willing to experiment, you can pick up go in a week or two. So, is it worth it?
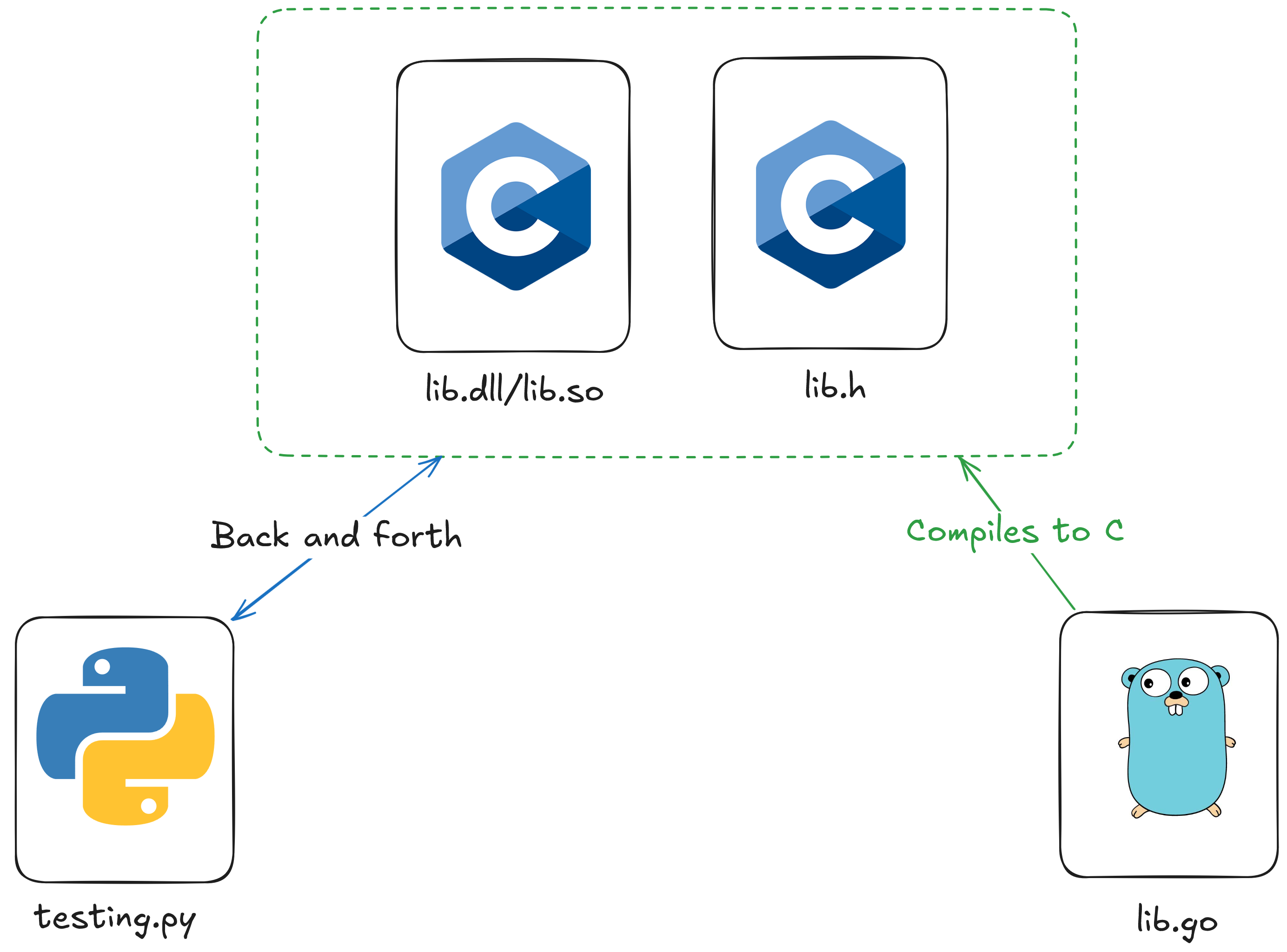
What is Dynamic Linking
*Some of the terms I’m using have multiple definitions, so not everywhere will match with what I say here
To start with, let’s understand a bit of what I’m doing. A shared library for the purposes of this article is a .dll (windows) or .so file. The purpose of these files is to allow you to share code and resources (images, fonts etc.) more easily. Essentially you can compile code and other resources into a shared library, and python can then import them. I will call this process dynamic linking.
Creating shared libraries is a feature of a ton of languages (go, rust, C#), so the skills from this post on the python side are transferrable to working with code from any of those languages. The basic setup for the code will be something like this:
Testing the hypothesis
First I needed to see if I should even bother. There’s a lot of back and forth that happens with this process between the languages, so is it actually worth doing? I decided to test 2 separate use cases. My approach was to create a shared library, dynamically link it in python, and use it to create a library in python that’s easy to use. Essentially for anyone using the library, they should have no idea that it’s calling to go in the first place. That last part is quite hard (more details later).
So the two test libraries I made were:
- A library to fetch details about websites for scraping. This would grab the URL, some headers and the content, and wrap it up into an easy to use class
- A library to calculate string similarity. This is the building blocks of something like an autocorrect feature for a CLI or application
I chose both of these because they were computationally expensive, and in the case of the web scraper, embarrassingly parallel. The type of tasks that I would usually end up reaching to go for. So with some napkin math, and quick and dirty measuring, how well did it end up?
Site Scraper
Go excels at multithreaded code, python really does not. I threw together a quick multithreaded system that requests a bunch of URL’s, gathers their data, and dumps it into a python object(s). The pure python implementation used requests and a ThreadPoolExecutor with 10 workers. The results were:
Pure python version took 17.39162588119507 seconds for 99 sites with:
Max CPU usage of 1.8
Peak System RAM usage of: 70.0 %
Go + python version took 4.625860929489136 seconds for 99 sites with:
Max CPU usage of 1.9
Peak System RAM usage of: 70.4 %
Memory difference is 0.4000000000000057% of 33444192256 Bytes
133776769.02400188 B
130641.0 KB
127.0 MB Meaning the Go version was significantly faster (~3.8x), and this gap got worse as you add more URL’s, but go used more peak memory. In general this memory usage only amounted to happening when the initial 3-4 lines of python code ran to process the requests, then went back down to parity. I think this is because I did not really optimize the go code much, so there were lots of extra copies of the data living in memory at one time, with optimizations you could get it pretty close to parity I think. The purpose wasn’t to create the best library, it was to see if working at a similar development speed to python I could whip something up that was much faster, and this certainly was. I spit out the demo for this in ~3.5 hours of coding (including research time to figure out how to do all this).
The API for the system also shook out to being pretty simple in python:
Site() # Main class that is interacted with
# Method to create a new site instance from a str of a url
Site.from_str(url:str)
# Method to create a list of site instances from a list of urls
Site.from_urls(urls:list[str])Easy to use, and fast. Not to mention this version you don’t need to mess around with any of pythons multithreading/multiprocessing, go handles all of it.
Similarity
This is one people may be less familiar with. String similarity is essentially a number between 0-1 that will tell you how similar two strings are. It’s the combination of the edit distance and a result as a normalized weight (between 0-1). So for example you might get something like this:
valid_words = ["init", "and", "or", "move"]
user_input = "mve" # Misspelled move
suggest_word(user_input, words) # Returns ("move", 85.71)Where it thinks mve is move with ~86% likelihood. This has uses in traditional autocorrect, or simpler issues. For example when you type in a prompt (such as at a CLI), you might mistype a command. When this happens we want some way to be able to suggest a similar valid command. I implemented the code as a more complicated library in go using indel similarity, which is faster but searches less completely than pure levenstein like most systems use. The only part that actually matters is the performance, so with a dictionary of ~370,000 words (from here) how quickly can we get a suggested word. You can see the full python version below:
Full python code (hidden to make reading easier)
def indel_similarity(inputString:str, targetString:str) -> float:
"""Calculates the indel similarity of two strings
Parameters
----------
inputString : str
The string you want to compare
targetString : str
The string you want to compare to
Returns
-------
float
The similarity (a normalized weight of the distance)
"""
inputLength, targetLength = len(inputString), len(targetString)
matrix = [[0 for _ in range(targetLength + 1)] for _ in range(inputLength + 1)]
for inputIndex in range(inputLength + 1):
matrix[inputIndex][0] = inputIndex
for targetIndex in range(targetLength + 1):
matrix[0][targetIndex] = targetIndex
for inputIndex in range(1, inputLength + 1):
for targetIndex in range(1, targetLength + 1):
if inputString[inputIndex - 1] == targetString[targetIndex - 1]:
matrix[inputIndex][targetIndex] = matrix[inputIndex - 1][targetIndex - 1]
else:
matrix[inputIndex][targetIndex] = min(matrix[inputIndex - 1][targetIndex] + 1, matrix[inputIndex][targetIndex - 1] + 1)
distance = matrix[inputLength][targetLength]
normalized_distance = distance / (inputLength + targetLength)
similarity = 1 - normalized_distance
return similarity
def suggestWord(input_string:str, valid_words:list[str]) -> list[str, float]:
"""Takes in a word and suggests a word from the list of valid words
Parameters
----------
input_string : str
The string to compare against valid words
valid_words : list[str]
The words that are considered valid
Returns
-------
list[str, float]
The suggested word, and the likelihood
"""
highest = 0.0
suggested_word = ""
for word in valid_words:
similarity = indel_similarity(input_string, word)
if similarity > highest:
highest = similarity
suggested_word = word
return suggested_word, highest
def load_words() -> list[str]:
"""Load a set of words from a text file
Returns
-------
list[str]
The list of words
"""
res = []
with open("words.txt", "r") as f:
for line in f.read().split():
res.append(line)
return resThe equivalent go code is a bit fancier, but roughly it would be the code below:
Full go code (hidden to make reading easier)
package main
import (
_ "embed"
"strings"
)
//go:embed words.txt
var wordsContent string
type Suggestion struct {
Likelihood float32
Word string
}
type DistanceAlgorithm func(inputString, targetString string) int
type SimilarityAlgorithm func(inputString, targetString string) float32
// Function that calculates the similarity of two strings using a distance algortithm
//
// # Parameters
//
// inputString (string): The first string to use for the comparison
// targetString (string): The second string to use for the comparison
// algorithm (DistanceAlgorithm): The algorithm to use to calculate the distance
//
// # Returns
//
// float32: The similarity (between 0-1, closer to 1 is more similar)
func CalculateSimilarity(inputString, targetString string, algorithm DistanceAlgorithm) float32 {
inputLength := len(inputString)
targetLength := len(targetString)
// Get the distance
distance := algorithm(inputString, targetString)
// Normalize your distance across the lengths of the inputs
normalized_distance := float32(distance) / (float32(inputLength) + float32(targetLength))
// Get the final similarity and return it
similarity := 1 - normalized_distance
return similarity
}
// Function that suggests the highest similarity word to the input string
//
// # Parameters
//
// inputString (string): The first string to use for the comparison
// validStrings ([]string): The valid words to check against
// algorithm (SimilarityAlgorithm): The algorithm to run and generate the similarity for
//
// # Returns
//
// float32: The similarity (between 0-1, closer to 1 is more similar)
func SuggestWord(inputString string, validStrings []string, algorithm SimilarityAlgorithm) Suggestion {
var (
highestRatio float32
result string
)
for _, currentString := range validStrings {
likelihood := algorithm(inputString, currentString)
if likelihood > highestRatio {
highestRatio = likelihood
result = currentString
}
}
return Suggestion{highestRatio, result}
}
// Calculates the Indel similarity of two strings
//
// # Parameters
// inputString (string): The first string to use for the comparison
// targetString (string): The second string to use for the comparison
//
// # Returns
// float32: The indel distance (between 0-1, closer to 1 is more similar)
func IndelSimilarity(inputString, targetString string) float32 {
similarity := CalculateSimilarity(inputString, targetString, IndelDistance)
return similarity
}
// Calculates the Indel distance of two strings
//
// # Parameters
// inputString (string): The first string to use for the comparison
// targetString (string): The second string to use for the comparison
//
// # Returns
// int: The indel distance (edit, delete distance)
func IndelDistance(inputString, targetString string) int {
inputLength := len(inputString)
targetLength := len(targetString)
// Construct initial matrix
matrix := make([][]int, inputLength+1)
for i := range matrix {
matrix[i] = make([]int, targetLength+1)
}
for inputIndex := 0; inputIndex <= inputLength; inputIndex++ {
matrix[inputIndex][0] = inputIndex
}
for targetIndex := 0; targetIndex <= targetLength; targetIndex++ {
matrix[0][targetIndex] = targetIndex
}
// Calculate indel matrix
for i := 1; i < inputLength+1; i++ {
for j := 1; j < targetLength+1; j++ {
if inputString[i-1] == targetString[j-1] {
matrix[i][j] = matrix[i-1][j-1]
} else {
matrix[i][j] = min((matrix[i-1][j] + 1), (matrix[i][j-1] + 1))
}
}
}
// Determine distance for the provided input
distance := matrix[inputLength][targetLength]
return distance
}Without comments the go code is 82 lines (without the wrapper library), and the python all in is 40. But the go is a general solution with any distance algorithm, and python is just for indel similarity. The go version was go+python, where the print statements and data passing were done in python, then go did the heavy lifting. The API for that was a single function:
# Returns a tuple with the suggested word first, and a float between 0-100 for the percentage of likelihood
spellcheck(word:str|bytes)
spellcheck("almni") # ("alumni", 85.71428656578064)Performance wise we got:
python returned:
The suggested word for almni is alumni with a ratio of 0.9090909090909091
Took 3254.749 miliseconds
Go returned:
The suggested word for almni is move with a likelihood of 85.71428656578064
Took 90.881 milisecondsSo roughly ~36x faster with go. This is also without any multithreading on either side to see if it was worth doing it for slow single-threaded tasks.
Conclusions
So, the system works, and it works well. 3-36x speedups in two common tasks is pretty good, but there’s also dragons here. I will have 2 other posts in this series walking through how to do this, but whether you should or not is up to you. If you choose to go this route be warned it’s a bit of a nightmare of undiagnosable problems sometimes. I was compiling on windows and several times for obscure reasons I ended up with compile errors stating:
$> go build -buildmode=c-shared -o lib.dll lib.go
command-line-arguments: open C:\\Users\\kiera\\AppData\\Local\\Temp\\go-build4281783149\\b001\\exe\\lib.dll: Operation did not complete successfully because the file contains a virus or potentially unwanted software.With what I encountered, it was one of maybe 3 potential issues:
- Because
%USERPROFILE\Tempis a protected route since apps store lots of data there, it was being extra careful - I used
//embedto embed a text file, which it saw as being malicious. Hackers will often include obfuscated code like this, so that makes sense. Unfortunately I tested the library usinggo run, so this issue only popped up right at the end, and I had nothing to go off to discover this was a potential issue - Windows assumes vaugely named DLL’s are dangerous. I used the name
lib.dllwhich combined with direct memory access made windows assume it was malware. In fact even when it compiled properly python wouldn’t let me importlib.dll
I changed the name to similarity.dll, and disabled my defender to compile, and everything worked. This is just a microcosm of the weirdness you can run into when going this route. Some of which is just trial and error to fix. If you corrupt memory for example, there’s no error message at all, your program just won’t run it will print messages until the error, then silently dies in the background. If you decode \r incorrectly, your print statements will break until the next \n in python and go making you think you have a memory corruption issue, but you just messed up your string parsing. If you misalign memory… You get the point. This was also all done on windows and tested on windows, managing all the different runtime environments I’m sure is another beast entirely.
So, whether it’s worth it or not is up to you, but if you have a use case, or are up for the challenge, check out the next post for details on how to do this.