Making categories simpler
scorch web optimization theory terminology
Crossposted from https://schulichignite.com/blog/taxonomical-ordering/
Table of contents
- Why categorize?
- What is a Hierarchy?
- What is a taxonomy?
- Other ways of organizing taxonomies
- How this works in code
- Online store
- Advantages of taxonomies
- Hierarchy is very common & saves effort
- Works well for change
- Examples of taxonomies
- Family tree
- Tags on this blog
- Animal taxonomy
- Other ways of doing this
- References
Why is a wolf different than a jellyfish? There are obvious differences, but how do we categorize something as more wolfey, or more jellyfishy? Structuring information is hard. Categorizing data that you have in a way that is useful and meaningful is something that anyone who has worked with blogs, eCommerce, or databases has run into.
Why categorize?
The whole reason we categorize things is to make it easy to find things that are similar. If we’re doing a painting and want to google something that looks like a wolf, then a jellyfish image is useless. Likewise if we want to buy a laptop, and a site keeps showing us books (ew) then it’s just a waste of time. We use categories in everything from blog posts, to online stores, to game vendors/merchants and more.
Since we don’t want to waste people’s time we go back to the question of how to organize things into a system that is useful. Luckily there are some common terms, and ways of managing this complexity. In particular their is taxonomical structuring/ordering (this is simpler than it sounds).
What is a Hierarchy?
A hierarchy is just a fancy name for a structure that shows categories that are related in some way to all of the categories beneath them. For example when talking about a location you might have a hierarchy that looks like this:
flowchart TD
a{Continent} & b{Country} & c{Province} & d{City}
a --contains--> b --contains-->c --contains--> d
Where the overall category is A location from there you have continents, which contain countries, which contain provinces, which contain cities.
What is a taxonomy?
A taxonomy is easiest to think of as a set of categories. They can be structured hierarchically, and allow you to organize your data effectively. They are useful when developing apps because they are recursively defined. This is just a fancy way of saying that a taxonomy can contain other taxonomies. This is useful because it means that you can easily gather all the data in a hierarchy from any place above or at the taxonomy you’re looking for.
Within a taxonomy you have terms, terms then have:
-
a parent (optional); A term that the current term is “part of” or “owned by” (i.e. A province is a “part of” a country)
-
a child (optional); A term that the current term “belongs to” or “owns” (i.e. A province “owns” a city)
-
entries/data/nodes; These are the actual entries for the terms (i.e. Calgary is a city, and therefore a node of the city taxonomy term). Typically these are references to whatever form the data exists in. For example if there’s a class representing a city, then this would be a reference to it (i.e. the term would have a list [or single reference] of objects/class instances of data associated with the term). Some taxonomy systems just make the data part of the terms.
So the taxonomy is the template/schema for how the data is structured, and then terms are the actual “categories” of the taxonomy, then nodes are where data lives. Here is what the example from earlier might look like:
flowchart TD
a{{Location}} <--Part of--> b{Continent} <--Part of--> c{Country} <--Part of--> d{Province} <--Part of--> e{City}
b <--Belongs too--> f((North America))
c <--Belongs to--> g((Canada))
d <--Belongs to--> h((Alberta))
e <--Belongs to--> i((Calgary))
In all diagrams from here on out:
-
anything in a hexagon is a taxonomy
-
anything inside a diamond is a term
-
anything in a circle is a node
-
The arrows are the relationship
You can also consider any terms/nodes that are children in a taxonomy to be “owned” by the taxonomy higher than them. You can then have more detailed examples that make it clear what taxonomy contains the others:
flowchart TD
AA{North America} & a{Canada} & b{Alberta} & c((Calgary))
AA --Is part of--> a
a --Is part of--> b --Is part of--> c
From the taxonomy tree below we can see that Alberta and British Columbia are part of Canada. Since they are linked as parent/child relationships we can go from any in either direction. So I can find out which province Calgary is in by checking the parent of that node, and I can check what cities are in British Columbia by checking the children of that node.
flowchart TD
AA{North America} & a{Canada} & b{Alberta} & c((Calgary)) & d{British Columbia} & e((Kelowna)) & f((Revelstoke))
AA --> a
a--> b & d
b--> c
d --> e & f
I can then also find any node so long as they have 1 term in common. So for example because Calgary and Kelowna are both in Canada (called ancestors) I can find them from each other by going two parents up and then down two children.
flowchart TD
a{Canada} & b{Alberta} & c((Calgary)) & d{British Columbia} & e((Kelowna))
c --parent--> b
b --parent--> a
d --child--> e
a --child--> d
This is the path to find Kelowna from Calgary; I can go to Calgary’s parent (Alberta), then to it’s parent (Canada), then to that nodes child (British Columbia), and then finally to Kelowna.
Other ways of organizing taxonomies
You can also use taxonomies without the hierarchy, this is handy for simple relationships (like tags in a blog), but generally should be avoided since there are better solutions for simpler relationships than taxonomies.
Additionally some taxonomy systems combine nodes & terms. In these systems the data is not a separate thing, and instead the terms themselves will contain information. This is useful in situations like the location information above since as we currently have it we can’t store information about anything other than cities. If we instead allowed our taxonomy terms to also store the data then we could have data at every level of the hierarchy.
How this works in code
Since this is a bit more complicated of a topic I have created an example repo with all the code necessary to see how this concept works in practice.
The examples in this article will not run in python. They have been simplified to make it easier to read. Additionally if you have never heard of type hints, they are used to define what data type each of the variables/attributes should be. For example a string variable called name would look like this:
name:strAnd if the variable can be empty inside a class there is a | and then the other option for the type. So str | None would mean the variable could be a string, or a None like this:
name: str|NoneFeel free to look at the example repo for a working implementation. A basic template of a taxonomy system would look like this:
class Term:
parent: Term | list[Term] | None
child: Term | list[Term] | None
content: list[Node]
class Node:
term: Term | list[Term] | NoneThe term class represents any sort of taxonomy term, and the Node class represents any sort of node you can think of. For each of the attributes they can either be lists, single instances, or None. The reason for this is that some relationships can overlap, while others should only have 1. A blog post might have multiple categories, but a person wouldn’t have multiple biological mothers. Use whichever makes sense.
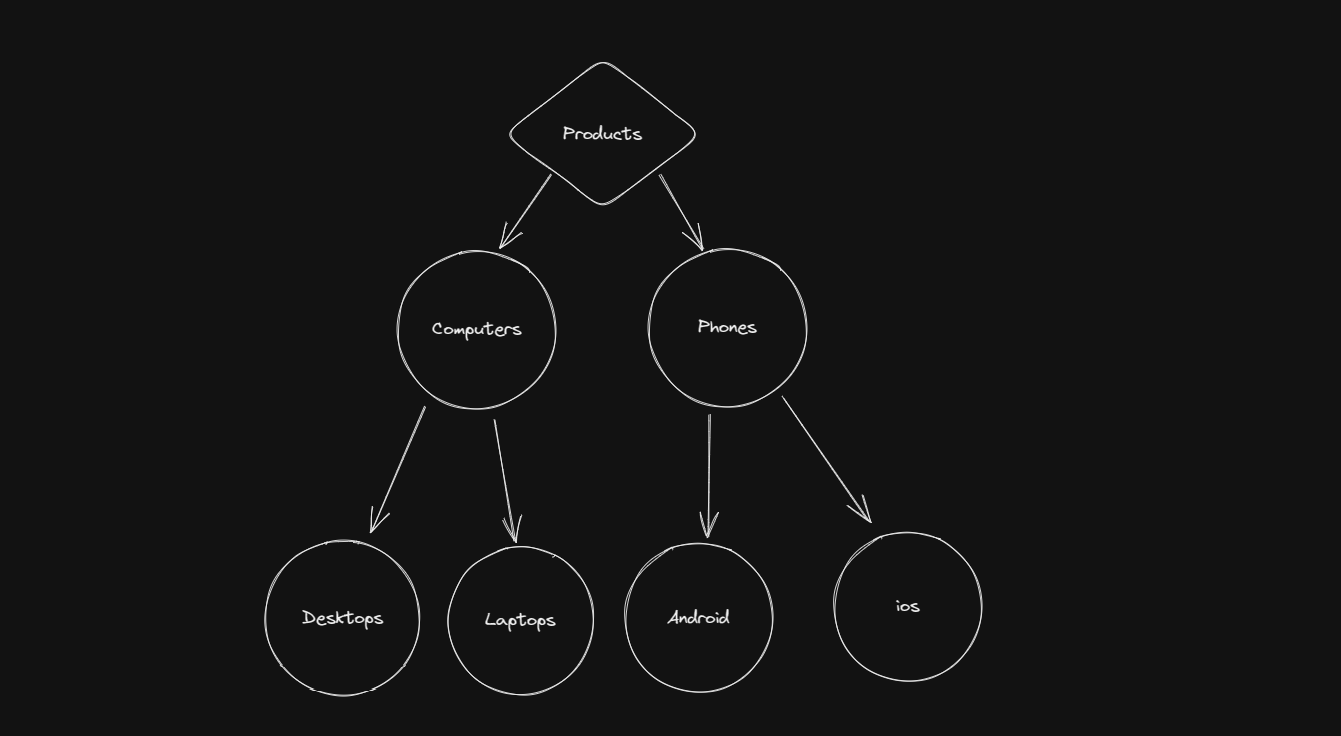
Online store
Imagine you have an online electronics store that has some product categories, and then products in those categories. The code looks roughly like this:
class Category:
name: str
parent: list[Category] | None
children: list[Category] | None
products: list[Product] | None
class Product:
name: str
category: Category|None
price: float
description: str
product_id: strEach Category optionally has a parent(s) and/or children, or a None if there is no parent(s)/children, and a list of Node’s (Product’s) representing the actual content associated with the tag. The reason everything is a list of Category’s or Products is because product categories have lots of overlap, so you might have a Category for a brand, that also fits in a Category for a type of product (like apple laptops being under an apple category, and a laptop category)
From this we can write functions that will get data we need those functions include:
-
Category.add_child(category:Category): A method to add a child to the list of children -
Category.add_product(product:Product): A method to add a child to the list of products -
Category.get_products()->list[Product]: Returns a list of all the products associated with a category, and all of it’s children
This means now that if we have a webpage that we want to include all the products in the “laptop” category, we just do:
laptops = Category("Laptops", [computers], [apple_laptops, windows_laptops], [laptop1,laptop2])
laptops.get_products()This means with 1 function call we get all the Product’s in the laptops object, and all the Product’s in the apple_laptops and windows_laptops Category’s! We were able to get every value in the taxonomy in one go!
Advantages of taxonomies
So why even do this in the first place? How are taxonomies better than just chucking all my data into a pool of objects and searching through them manually?
Hierarchy is very common & saves effort
Tons of data is hierarchical, which means that using taxonomies can save you a lot of time organizing your data. If we were using our location example from earlier without a taxonomy, and instead just had a Location object we would have to fill out a ton of fields to capture the same data. But with hierarchies, if we just add a new city, we only have to add it to the term just above it in the structure (province).
Works well for change
Imagine our previous example of a location. Let’s say we had an old system, and in 30 years it’s common for people to live on another planet. I could just add a planet term to the top of the taxonomy, put everything under the Earth term, and our whole system still works!
Examples of taxonomies
There are a near infinite number of taxonomies (basically anything that can be categorized). But here are some examples of taxonomies that are common.
Family tree
flowchart TD
a{Great Grandma 1} & b{Great Grampa 1} & c{Great Grandma 2} & d{Great Grampa 2} & G{{Family Tree}}
G --> a & b & c & d & A & B & C & D
a & b --> e{Grandma}
c & d --> f{Grampa}
e & f --> g{mum}
A{Great Grandma 3} & B{Great Grampa 3} & C{Great Grandma 4} & D{Great Grampa 4}
A & B --> E{Grandma}
C & D --> F{Grampa}
E & F --> h{dad}
g & h--> i{child}
Tags on this blog
For the ignite blog we have a tagging system used to categorize our posts. You can see all our tags here. In this case the terms are the tags, and the nodes are the pages for the blog posts.
Since there is no hierarchy (no tags nested under other tags), this could be implemented in simpler code:
class Tag:
name: str
posts: list[Post] | None
class Post:
title: str
subtitle: str
description: "..."
tags: list[Tag]|None
content: str
url: strSince there is only a single layer of tags that lead straight to the content we don’t need any of the parent/child relationships. Down the road if we did need them, we just need to add those two fields back into the Tag class. Here is an example of what this would look like with 3 articles from the blog (How to cheat at CSS, The dangers of CDN’s, and Stealing like a developer):
flowchart TD
A{{tags}} & C{Scorch} & D{Web}
A --> C & D & E & F & G & AA & AB & Q & V & W & X & FF & S
C & D & F & Q{html} & V{js} & W{networking} & X{security} --> E((The dangers of CDN's))
C & D & G & F{css} & G{design} & AA{ui-ux} & AB{frontend} --> I((How to cheat at CSS))
C & D & S{legal} & FF{open source} --> WW((Stealing like a developer))
Animal taxonomy
This is one of the most complicated taxonomy systems. If you’re a site like inaturalist, you need some way to organize this info (they have ove 412 thousand species!). You can actually see the inaturalist taxonomy for animals here.
One way (the most common) to represent biological taxonomy structure would be like this:
flowchart TD
A{Kingdon} & B{Phylum} & C{Class} & D{Order} & E{Family} & F{Genus} & G((Species))
A <--> B <--> C <--> D <--> E <--> F <--> G
Which then might have some actual entries like this:
flowchart TD
A{Animal}
A --> AA{Arthropoda} --> AAA{Chelicerata} --> AAAA{Xiphosura} --> AAAAA{Limulidae} --> AAAAAAA{Incertae sedis} --> AAAAAAAA((Horseshoe crabs))
AA --> AAB{Crustacea} --> AABA{Malacostraca} --> AABAA{Decapoda} --> AABAAA{Nephropidae} --> AABAAAA((Lobsters))
AABAA --> AACAAA{Pleocyemata} --> AADAAAA((Shrimp))
Where each of the terms are just the kingdom, pyhlum, class, order, family or genus and then at the end there is a species that is a node with additional data about where it lives, what it eats etc.
Other ways of doing this
Some of these sorts of systems can be very simple (only 1 item in the hierarchy because the categories speak for themselves), and you might want to go about them differently.
For example you might have a taxonomy system for a directory on a website, that lists by position in a company, and alphabetically, something like this:
flowchart TD
AA{{Roles}} & a{manager} & b{developer}
AA --> a
AA --> b
Where you might have some nodes attached to manager and developer that you want to list alphabetically. To do this, you might want to instead setup something that looks like this (developer is removed for simplicity):
flowchart TD
AA{{Roles}} & a{manager} & d{A} & e{B} & f{...} & g{Z} & h((Bob)) & I((Alice)) & J((Zeke))
AA --> a
a --> d
a --> e
a --> f
a --> g
d --> I & K((Aaron)) & L((Abby))
e --> h & M((Brian)) & N((Brent))
g --> J
In this case since you know you are going to go alphabetically, it’s worthwhile to have each person be filed under the first letter of their name within their role. This has a few performance advantages in many cases. For example let’s say you had 200 managers, and only 15 start with the letter b. If you know someone is looking for a manager starting with b you have cut out 185 other possible search terms in the worst case.
Now imagine you do this with something like news posts, instead of letters you might add which year something was published to the taxonomy, then categorize each of the tags under the year.
flowchart TD
AA{{stories}} & a{2013} & b{...} & c{2023} & d{Crime}
AA --> a & b & c
a -->d & e{tech} & f{finance} & g{...} & h{politics}
c -->dd{Crime} & ee{tech} & ff{finance} & gg{...} & hh{politics}
d & e & f --> Q((Man robs atm with fork))
d & h & e --> A((Voting rigged, or counting is hard))
dd & hh & ee & ff --> QQ((...))
dd & ee --> AAA((...))
You only have to look at a small portion of the overall taxonomy to find what you want. If you posted 3 articles a day for the last 10 years (10,950 articles), and someone wants a particular articles about a crime in 2013 (let’s say there were 85 of those), you have cut down the search space from 10,950 articles to 85 articles (99.3% reduction). In our case we only need the 2013 term, and from that term we only need the crime term:
flowchart TD
AA{{stories}} & a{2013} & d{Crime}
AA --> a
a -->d
d --> Q((Man robs atm with fork))
d --> A((Voting rigged, or counting is hard))
This means we can skip every story under 2014-2023, and every story inside 2013 that does not have the crime tag!